![Image de couverture de l'article [Data Science] Et si on faisait du machine learning en analysant notre propre blog ?](/build/pictures/wanadev_main_header.webp)
L'agence
WanadevStudio
[Data Science] Et si on faisait du machine learning en analysant notre propre blog ?

J'ai décidé de conduire une courte expérience de machine learning appliqué à un sujet que nous connaissons bien : nous, wanadev.
Machine Learning et web : notre blog comme sujet de départ
Les membres de l'équipe écrivent régulièrement des articles de blog sur des sujets diverses et variés, liés aux activités de l'entreprise ou de ses centres d'intérêts. À l'heure où j'écris cet article, il y a 130 articles disponibles sur le blog, de 2014 à aujourd'hui.
Fort de ce constat, je me suis posé la question suivante : peut-on tirer des conclusions sur notre façon de travailler, notre communication, notre vision commune ?
Je me suis donc lancé, armé de python et de word2vec, un projet de google permettant l'analyse du contexte linguistique des mots.
Pour une partie du code, je me suis inspiré de cet article par Anindya Roy, qui est très bien rédigé, je vous conseille d'aller y jeter un oeil.
Décrivons les étapes de l'expérience.
1 ) Machine Learning et web : la récupération de données
C'est l'étape la plus longue et fastidieuse, et elle est pourtant cruciale au bon fonctionnement de notre modèle de machine learning.
Les données doivent être collectées, assainies, "tokenisées" (ou tokenized en anglais, c'est à dire transformées en éléments unitaires facilement identifiables par la machine).
1.1 ) Collection de données
Il est bien sur hors de question de copier-coller le contenu des 130 articles à la main. J'utilise alors Scrapy, une librairie python permettant de "scraper" (c'est à dire parcourir automatiquement un site web en suivant des liens) les différentes pages des articles du blog.
@ Scrapy permet de récupérer le contenu HTML des pages web, mais aussi de parcourir le DOM en utilisant la syntaxe du CSS.
Dans notre cas, on va inspecter la landing page du blog de wanadev et remarquer tout de suite que les liens vers les articles nous sont présentés par 10, et ils sont tous imbriqués de la façon suivante :

Une bonne syntaxe css pour récupérer le lien vers l'article serait donc.latest-post-one h6 a a puis récupérer la valeur de la propriété href. On peut faire ça pour les 10 articles de la page puis ensuite sur toutes les autres pages du blog.
Une fois dans l'article, on veut récupérer tout ce qui est du texte dans l'article. En suivant le même procédé, on obtient .blog-post-content-container *::text.
Le code complet est ci-dessous :
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://www.wanadev.fr/blog/?page=' + str(i) for i in range(0, 14)] # 14 pages de blog à récupérer
def parse_content(self, response):
result = dict()
result['title'] = response.css('.container-blog-post-info + p::text').extract_first()
result['text'] = ""
for element in response.css('.blog-post-content-container *::text').extract():
result['text'] += element + "\n"
yield result
def parse(self, response):
print('Page : ' + response.url)
for article in response.css('.latest-post-one h6 a'):
yield response.follow(article.css('::attr(href)').extract_first(), self.parse_content)On lance scrapy en lui demandant du format json :
scrapy runspider crawl_wanadev.py -o wanadev.json -t json --nolog
Et hop ! on obtient en sortie un json de la forme suivante :
[{
"title": "\n\t\t\t\tOpenGL, \u00e7a a d\u00e9j\u00e0 25 ans ! ...,
"text": "\n\t\t\t\t\nEn quoi Vulkan est il l\u2019\u00e9volution ...
},
{
"title": "\n\t\t\t\tGoogle Cloud offre depuis quelques ann\u00e9es de pl...,
"text": "\n\t\t\t\t\nL'utilisation des services Google se font g\u00e9n\u00e9r...
},
...
]1.2 ) Machine Learning : assainissement et tokenisation
Bon, premièrement on voit tout de suite qu'on a une multitude de caractères non désirés : des \n (saut de ligne) et \t (tabulation) qui n'apportent aucune valeur sémantique, comme n'importe quel séparateur. On va donc les enlever.
On va aussi apparemment avoir des problèmes d'encodage, avec les \u00e7a et autres \u00e9j que sont les accents et apostrophes. On va essayer de transformer les apostrophes en séparateurs, et les accents en leur équivalent non accentué.
Cette transformation va nous faire perdre un peu d'information ("à" en français n'est pas la même chose sémantiquement que "a"), mais on va gagner en simplicité.
Dernière chose : on met tout en minuscules. On n'a pas de différence de sens entre "Aujourd'hui" et "aujourd'hui", et pourtant notre système fera la différence entre les deux, ce qui est indésirable.
Enfin on "tokénise" : on crée une liste de mots en découpant à chaque séparateur.
Un peu de code vaut mieux que 1000 mots :
def remove_accents(text):
nkfd_form = unicodedata.normalize('NFKD', text)
return u"".join([c for c in nkfd_form if not unicodedata.combining(c)])
def tokenize(text):
return re.sub("\s+", " ", re.sub("[^A-Za-z]", " ", remove_accents(text))).split()
with open('wanadev.json') as f:
data = json.load(f)
# Concatenation du header et du texte de l'article
text = [i["title"] + "\n" + i["text"] for i in data]
# Token + minuscules
text_data = [tokenize(item.lower()) for item in text]Ensuite, il convient de toujours vérifier un minimum ses données :
print(text_data[0])
# ['que', 'de', 'chemin', 'parcouru', 'depuis', 'avril', '2009', 'date', 'de', 'naissance', 'de', 'wanadev', 'd',...]@ En poussant un peu la vérification, je me suis rendu compte que certains articles avaient des blocs de code, qu'il aurait fallu filtrer dans le scraping des pages. J'ai décidé de l'ignorer pour le moment, on aura un dictionnaire étoffé de mots de code, peu intéressants pour notre analyse, mais relativement peu gênants vu qu'il y aura peu de mots en commun avec le dictionnaire français.
2) Un peu de théorie
Il convient, avant d'aller plus loin, de bien comprendre le fonctionnement de word2vec et ce qu'il nous permet d'obtenir.
Word2Vec, comme son nom l'indique, transforme des mots en vecteur (un ensemble de nombres réels), et ces vecteurs de nombres sont les seules choses que la machine peut traiter.
En machine learning, quand on a des dictionnaires du genre <A, B, C, D, E>, on utilise souvent le one-hot encoding.
Le one-hot encoding, c'est transformer ces valeurs discrètes en vecteurs de cette forme (0, 0, 0, 0, 0, ...., 1, ..., 0, 0), qui ont pour dimension la taille de notre dictionnaire.
Dans notre cas un one-hot encoding possible est :
A => (1, 0, 0, 0, 0)
B => (0, 1, 0, 0, 0)
C => (0, 0, 1, 0, 0)
D => (0, 0, 0, 1, 0)
E => (0, 0, 0, 0, 1)^ Le problème avec cet encodage, est que si le dictionnaire est grand, nos vecteurs seront de grande dimension. En machine learning, on appelle cela le fléau de la dimension. Une dimension élevée implique un apprentissage très long, nécessitant beaucoup de données, on va donc chercher à la réduire.
Et c'est là que Word2Vec entre en jeu !
Word2Vec réalise ce qu'on appelle des embeddings, ou en français des Représentations vectorielles continues. Il s'agit de réduire la dimension de ces vecteurs, en établissant des relations entre eux.
Prenons un exemple :
Si notre dictionnaire est construit par la phrase "le chat pourchasse la souris", il sera constitué de 5 mots, comme notre exemple plus haut. ['le', 'la', 'pourchasse', 'chat', 'souris']. On peut faire des rapprochements entre ces mots, "chat" est proche de "souris" et "le" est proche de "la". On pourrait même tracer un axe :
----le---la-----------pourchasse--------chat---*souris--->
On aura d'abord réduit la dimension de notre encodage de 5 à 1, mais en plus on l'aura fait intelligemment, car cet axe mesure la proximité du mot avec le champ lexical de l'animal. Et le faire intelligemment est crucial si on veut que notre système de machine learning qui va récupérer ces données soit nourri avec la véritable information qui est le sens des mots.
Word2Vec va faire ce travail pour nous. Il va prendre un ensemble de phrases en entrée, va analyser chaque mot avec son contexte (les mots environnant) et va apprendre les rapprochements entre mots.
@ Si "chat" et "souris" sont souvent dans le même contexte, alors word2vec va comprendre qu'ils sont proches.
Je ne vais pas rentrer plus dans le détail du fonctionnement de word2vec, mais très synthétiquement, un modèle de word2vec est un simple réseau neuronal à 2 couches : 1 couche cachée, et 1 couche softmax en sortie qui sera de la dimension désirée de notre représentation vectorielle continue, généralement entre 100 et 1000.
Ces représentations vectorielles sont destinées à être fournies à un système de machine learning en aval, mais on peut tout de même en tirer des conclusions rien qu'en les analysant simplement à la main ! Le plus utile, à mon sens, est de se pencher sur les distances entre mots que word2vec calcule, et en déduire un biais dans notre manière de communiquer. Nous verrons cela un peu plus bas.
3) L'entraînement du modèle
Passons au concret, on va entraîner notre modèle pour obtenir ces fameux vecteurs.
On prend une fenêtre de 10 mots, pour commencer. On va également, pour pouvoir sortir de jolis graphes, réduire la dimension à 2.
^ Il faut bien se rendre compte que c'est trop peu pour représenter efficacement nos mots. Ce graphe nous permettra juste d'étudier des similarités générales, s'il y en a.
try:
model = gensim.models.Word2Vec.load("word2vec.model") # chargement du modèle
except IOError:
model = gensim.models.Word2Vec(text_data, size=2, window=10, workers=24, min_count=1) # ré-entrainement, uniquement si besoin
# sauvegarde sur disque
model.save("word2vec.model")
# liste de mots à étudier
word_list = ['3d', 'mon', 'ma', 'son', 'sa', 'technique', 'rendu', 'solution', 'wanadev', 'entreprise', 'yannick', 'fabien', 'baptiste', 'pierre', 'benjamin', 'docker', 'container', 'moteur', 'manuel', 'come', 'api', 'web', 'webgl', 'vr', 'client', 'projet', 'le', 'la', 'comme', 'avec', 'pour']
# graphe
for word in word_list:
plt.scatter(model.wv[word][0], model.wv[word][1])
plt.annotate(word, xy=(model.wv[word][0:2]))
plt.show()Admirons le résultat :
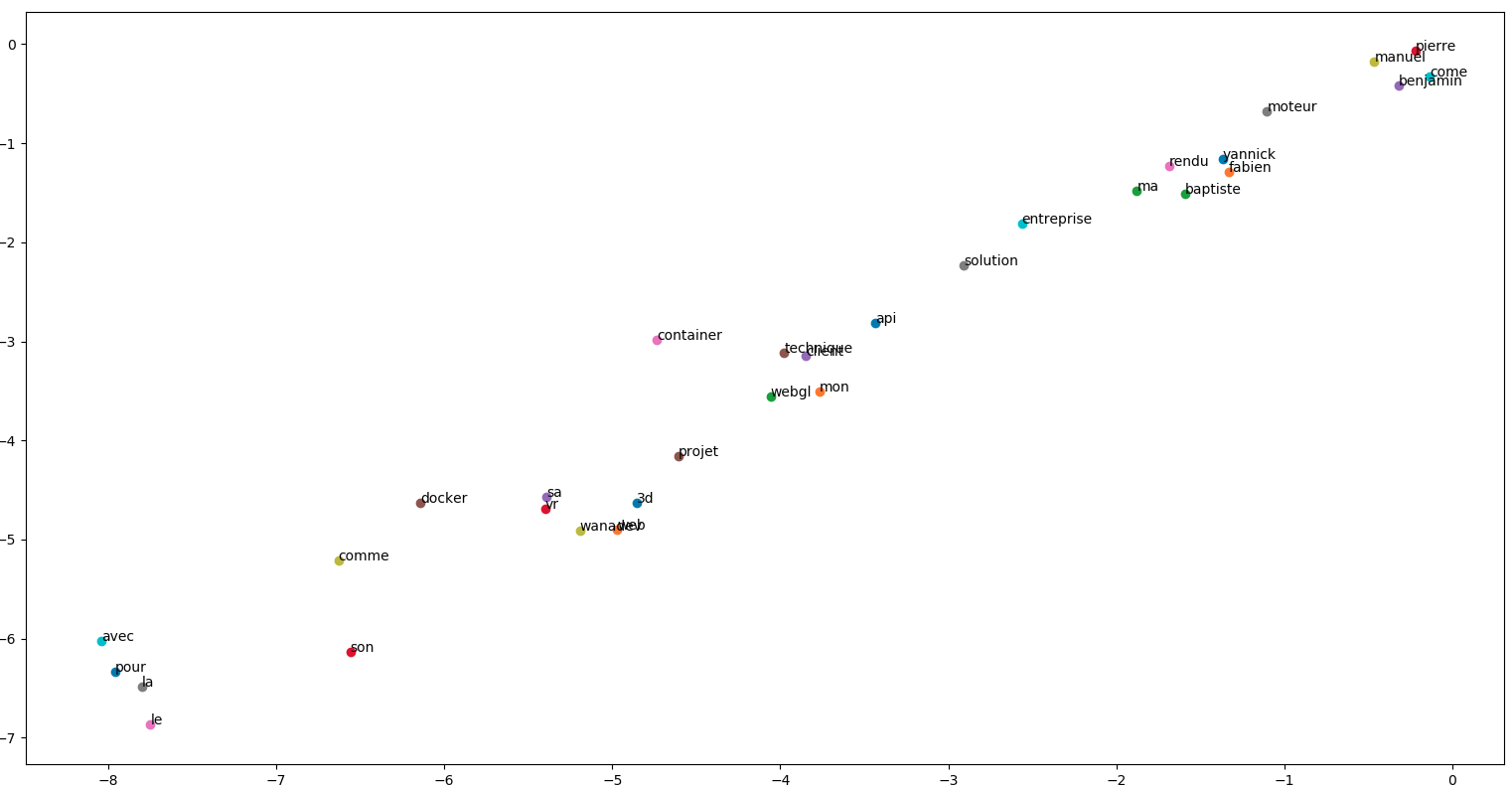
Les regroupements de mots sont intéressants dans ce graphe. Pour rappel : word2vec va essayer de regrouper les mots qui se retrouvent souvent dans le même contexte.
On a déjà une bonne nouvelle qui valide notre démarche, les prénoms se retrouvent tous ensemble dans le coin supérieur droit, et les mots d'usage généraux (le, la, est, ...) sont plutôt dans le coin inférieur gauche.
On note également que les secteurs d'activités de wanadev ("3d", "web", "vr") sont considérés comme proche du mot "wanadev", ce qui semble logique.
^ On ne peut pas vraiment tirer de conclusion de ce graphe, la dimension du vecteur en sortie étant trop faible. On valide juste que ces vecteurs sont cohérents, que les mots qui se ressemblent sont bien proches.
Alors comment tirer des enseignements de cette expérience ? D'abord essayons de sortir des vecteurs de plus haute dimension, qui pourront donc contenir plus d'information sémantique.
Pour choisir la dimension du vecteur, on procède à une méthode empirique : on prend la racine 4ème de la taille du dictionnaire.
print(len(model.wv.vocab) ** 0.25)
# 10.501497897776218Essayons donc des vecteurs de dimension 10. Nous ne pourrons pas les afficher en graphe, à moins de procéder à d'autres méthodes de réduction de la dimension, comme l'analyse des componantes principales (PCA), ou plus populaire l'algorithme t-SNE . En revanche, on peut afficher les distances entre mots pour en déduire des similarités. Essayons :
print(model.most_similar(positive=["docker"], topn=10))
# [('run', 0.9995599985122681), ('home', 0.9995294213294983), ('mon', 0.9994815587997437), ('debian', 0.9994770288467407), ('start', 0.9994732737541199), ('ga', 0.9994444847106934), ('bundle', 0.9994416236877441), ('document', 0.9994413256645203), ('php', 0.9994281530380249), ('server', 0.9994097948074341)]On retrouve bien les mots qui sont souvent utilisés avec docker. Essayons quelque chose de plus large :
print(model.most_similar(positive=["realite", "virtuelle"], topn=10))
# [('augmentee', 0.9668509364128113), ('explosion', 0.9624768495559692), ('explose', 0.9429628849029541), ('fantastique', 0.9266117811203003), ('mixte', 0.9211690425872803), ('indeniable', 0.921022891998291), ('multijoueur', 0.9138206243515015), ('pousse', 0.909371018409729), ('la', 0.9093440771102905), ('comprise', 0.9066435098648071)]Ou plus sentimental :
print(model.most_similar(positive=["fantastique", "incroyable"], topn=10))
# [('formation', 0.9900420904159546), ('casques', 0.9896398186683655), ('debuter', 0.9894623756408691), ('mobile', 0.9893956780433655), ('dedie', 0.9889820218086243), ('vr', 0.9887306690216064), ('reelle', 0.9886756539344788), ('gamme', 0.9886042475700378), ('reference', 0.988581657409668), ('salon', 0.9885084629058838)]print(model.most_similar(positive=["difficile", "complexe"], topn=10))
# [('facile', 0.9994938373565674), ('chose', 0.9994683861732483), ('encore', 0.9994561672210693), ('interessant', 0.999423086643219), ('simple', 0.9994222521781921), ('ca', 0.999413788318634), ('alors', 0.9994041919708252), ('tres', 0.9993925094604492), ('savoir', 0.9993826150894165), ('donc', 0.9993360042572021)]Machine Learning et blog Wanadev : que peut-on en tirer ?
Et bien déjà il faut savoir que notre corpus est assez petit (132 542 mots, dont 12 162 mots uniques), donc il y aura beaucoup de bruit statistique. On peut cependant observer certaines tendances :
- Nous parlons de la réalité virtuelle comme quelque chose de novateur, qui est en pleine explosion, fantastique etc... Beaucoup de qualificatifs très positifs qui traduisent notre engagement sur le sujet.
- Dans la même veine, en cherchant les qualificatifs positifs, on voit qu'ils sont souvent associés à des domaines métier, à des technologies ou à des événements : formation, mobile, salon, casques ... Pas surprenant, vu que les articles du blog vantent souvent les mérites du sujet traité.
- Notre dernière constatation est un peu plus parlante : les termes "difficile" et "complexe" sont étonnamment associés à "facile", "simple" et "intéressant". Cela traduit sans doute que les articles comparent des technos, des expériences, et que la difficulté est plus perçue comme un challenge que comme une fatalité.
Vérifions directement dans le corpus :
- "les microservices c'est une solution extrêmement flexible mais complexe"
- "Des profils "ingé" ont évidement une facilité à trouver des solutions à des problématiques complexes."
- "déployer est devenu quelques chose de complexe. L'objectif de rendre plus simple les process devenait alors évident."
Dernière chose, il faut savoir que ces représentations vectorielles continues que nous avons créé font en général partie d'un système de machine learning à plus grande échelle. On s'en sert par exemple pour comprendre, classer ou filtrer des commentaires de réseaux sociaux.
Machine Learning et notre blog : en conclusion
Ces résultats sont intéressants pour observer des tendances sur des éventuels biais de communication.
Le corpus étant le blog de Wanadev, il y a peu de leçons à en tirer ou de pistes d'amélioration, mais on peut réitérer l'expérience avec un corpus plus intéressant à analyser, comme par exemple la façon dont les autres parlent de Wanadev sur le web.
On pourrait alors en déduire des choses plus révélatrices : à quels termes sommes-nous associés ? l'opinion est-elle plutôt favorable ?
Alors peut-être pourrons-nous adapter la façon de communiquer (ou nous adapter / nous améliorer dans nos articles) en comprenant mieux comment les autres nous perçoivent.
-
 Créez votre assistant personnel grâce à Gmail et ChatGPT 4
Créez votre assistant personnel grâce à Gmail et ChatGPT 4Il y a 5 mois
Les LLMs, ou Large Language Models, comme ChatGPT, Llama2, Claude ou encore Mistral nous donne un avant-goût du futur des assistants virtuels tels que nous les connaissons avec Google, Siri ou Alexa. Pourtant, il manque une sacrée touche personnelle avec ces assistants nouvelle génération. Même si OpenAI a mis en place un système permettant d’à peu près personnaliser son expérience avec ChatGPT, nous sommes loin d’avoir des IA qui nous connaissent réellement. La raison est assez simple : ceux-ci n’ont pas accès à vos données. Et si on aidait ces LLMs si puissant en leur donnant des données pour qu’ils sachent répondre à des requêtes très personnalisées ?
-
 Tests automatiques fonctionnels d’applications 2D/3D
Tests automatiques fonctionnels d’applications 2D/3DIl y a 2 ans
Comme nous le disions dans cet article, l’automatisation des tests dans le développement logiciel est indispensable : dès lors qu’une application commence à avoir un minimum d’importance, les tests automatiques permettront de gagner énormément de temps en évitant de reproduire ad vitam æternam les mêmes tests manuels, et éviteront beaucoup de régressions. Dans cet article, nous allons présenter différents types de tests automatiques dans le cadre plus spécifique d’applications 2D/3D, puisque c’est ce que nous faisons ! Cela va du test basique qui clique sur 3 boutons aux tests de plusieurs minutes reproduisant les actions comme un véritable utilisateur. Accrochez-vous, c’est parti !
-
 Lambda : le juste prix !Recherche et développement
Lambda : le juste prix !Recherche et développementIl y a 4 ans
On a tous connu et on connaît encore des projets développés en un seul bloc d'une façon monolithique. C’est la structure classique d’un projet. En grossissant, il gagne en fonctionnalités et devient rapidement trop complexe, trop lourd, difficile à faire évoluer et surtout incapable à gérer des pics de charge. Pour éviter cela, un concept est apparu après les années 2000 : les microservices.
-
 Collaborer en réalité virtuelle : retour d'expérience et tour d'horizon des outils disponibles
Collaborer en réalité virtuelle : retour d'expérience et tour d'horizon des outils disponiblesIl y a 4 ans
En ces temps de télétravail et de confinement, pouvoir collaborer avec ses collègues le plus naturellement possible est un enjeu majeur pour être aussi efficace que possible et pour conserver le lien social fort qui nous relie tous chez Wanadev (les copains vous me manquez déjà !).
-
 La culture de l'open source chez WanadevRecherche et développement
La culture de l'open source chez WanadevRecherche et développementIl y a 4 ans
Chez Wanadev, l'utilisation et la contribution à l'écosystème open source est aujourd'hui une évidence, et ce n'est pas prêt de changer : c'est inscrit dans notre ADN. Dans cet article, et dans quelques autres qui vont suivre, je vais vous expliquer pourquoi et comment l'équipe contribue à l'open source, et quelle est notre culture d'entreprise à ce sujet.
-
Le meilleur cloud est celui qui n'existe pas encore !Recherche et développement
Il y a 4 ans
Ce n'est plus à démontrer, le monde actuel fonctionne en grande partie grâce à internet. En coulisses, de nombreux acteurs techniques fourmillent pour proposer des solutions adaptées à la forte croissance du marché et aux nouveaux usages. Entre eux, la concurrence fait rage et le cloud est le nouvel eldorado. Côté consommateur, l'offre paraît complexe et suscite souvent plus de questions que de réponses.





Commentaires
Il n'y a actuellement aucun commentaire. Soyez le premier !