

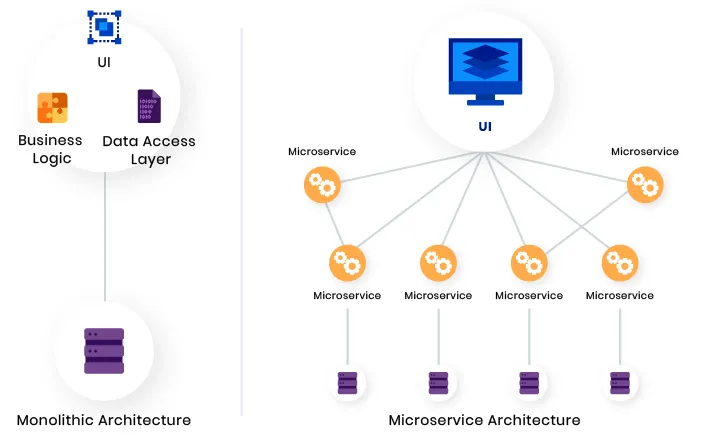
On a tous connu et on connaît encore des projets développés en un seul bloc d'une façon monolithique. C’est la structure classique d’un projet. En grossissant, il gagne en fonctionnalités et devient rapidement trop complexe, trop lourd, difficile à faire évoluer et surtout incapable à gérer des pics de charge. Pour éviter cela, un concept est apparu après les années 2000 : les microservices.
La lambda, tu sais pourquoi ?
Donc faire du microservice consiste à éclater un projet en plusieurs parties (en services) qui vont exécuter des tâches indépendamment. Plusieurs avantages à cela, la scalabilité, l’évolutivité et la maintenance.
 https://prog.world/best-architecture-for-mvp-monolith-soa-microservices-or-serverless-part-2/
https://prog.world/best-architecture-for-mvp-monolith-soa-microservices-or-serverless-part-2/
Si une architecture microservices est d'abord une notion théorique de développement, il est important de connaître quelles sont les solutions techniques et pratiques rattachées. Héberger ces services sur une même machine ? Utiliser docker sur plusieurs serveurs dédiés ? Utiliser un orchestrateur type Kubernetes ? Comment faire communiquer les services entre eux ? Comment gérer les déploiements ?
Le FaaS (Fonction as a Service) répond en majorité à cette problématique avec pour principe l'isolation de chaque fonction d'un projet. Sur ce terrain, AWS (Amazon) s'est positionné en pionnier avec son service Lambda créé en 2014. Ensuite est arrivé Google Cloud Platform avec App Engine puis Azure avec Functions.
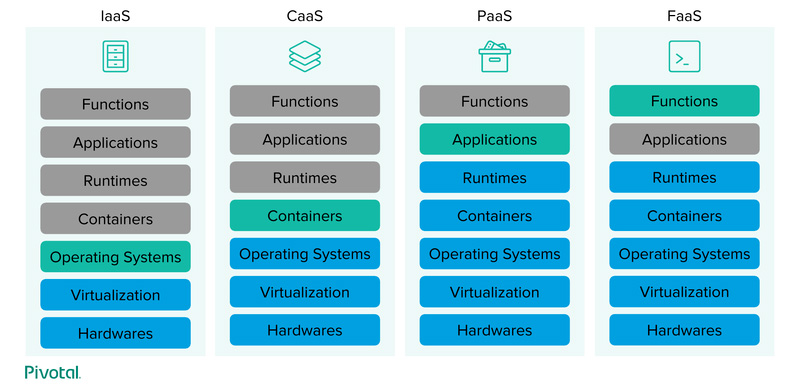
Une Lambda est une fonction hébergée sur une instance autonome et exécutée à partir d’un événement. De par sa conception, une Lambda est Stateless* et Serverless**. Les fonctions Lambda supportent nativement NodeJS, Python, Java, Go, Ruby et C#. Toutefois, il est possible d’utiliser des runtimes personnalisés pour d'autres langages.
Le grand principe des Lambda (λ) réside dans le montage et le démontage automatique des instances en fonction de la charge. Lorsque votre fonction est appelée, AWS va utiliser les instances déjà démarrées et si elles ne sont pas disponibles, il va en démarrer des nouvelles. Ainsi, théoriquement, votre fonction peut être exécutée de très nombreuses fois sans limitation physique d'un serveur.
Les cas d’utilisation de Lambda sont très vastes comme par exemple les traitements lourds (vignettage d’image, import CSV, calculs), comme worker d'une file de messages et plus communément pour le développement d’API .
Il y a quoi dans la vitrine ?
Comment nous l’avons dit en début d'article, le déclenchement d’une fonction est événementiel. Ainsi vous pouvez lancer une Lambda via un scheduler (d'une manière programmée dans le temps), après la modification d’un compartiment S3, à la réception d'un nouveau message dans SQS ou par un appel HTTP en passant par API Gateway. Dans ce dernier cas, vous pouvez paramétrer une route API qui exécutera votre fonction. Vous pouvez retrouver la liste des services qui peuvent déclencher une Lambda sur cette page.
Bon, sur le papier, λ c'est vraiment bien : flexibilité, faible coût (je spoil la dernière partie de l'article) et performance. Pas une ombre au tableau ? Comment gérer son authentification sur toutes ces lambdas sans dupliquer le code ? Comment gérer des configurations communes ? Les environnements ? Comment remplacer des nouvelles instances sans coupure ?
Ouvrons la boîte à outils.
Gérer l'authentification
Si vous souhaitez mettre en place une authentification devant vos fonctions, vous pouvez utiliser Authorizer. En réalité, il s'agit d'une lambda qui se positionne avant votre fonction pour vérifier la validité des informations d'authentification. Vous pouvez utiliser du JWT, du IAM (authentification des droits dans AWS) ou développer un système à votre sauce. Si l'authentification est réussie, l'authorizer renverra des entêtes spécifiques du contexte (l'utilisateur connecté par exemple) à la fonction suivante. Pour des meilleures performances, vous pouvez activer la mise en cache de l'authorizer.
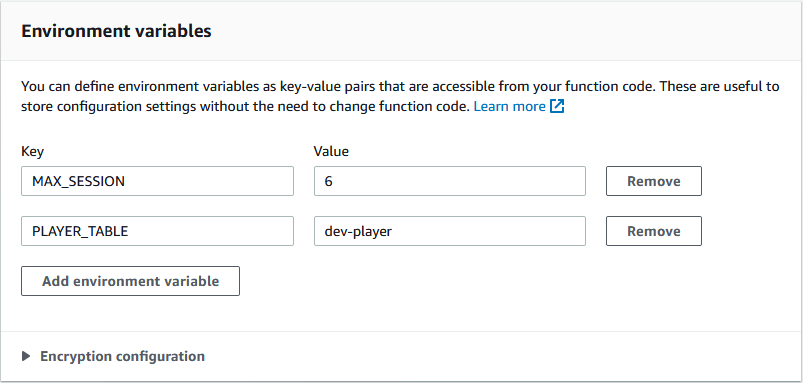
Les variables d'environnement
Difficile d'avoir un script complètement autonome, stateless, sans aucune configuration. Que cela soit pour stocker une clé API, une URL ou du paramétrage, il faut pouvoir injecter des variables à vos fonctions. AWS met à disposition un système de variables d'environnement globales et/ou par fonction.
Le déploiement
Le déploiement d'une fonction n'est pas si simple surtout si elle est rattachée à d'autres services. CloudFormation permet de créer des workflows de déploiement d'une stack pour automatiser ces tâches comme :
- La mise à jour des services de la stack (API gateway, Lambdas…)
- Ajout des nouvelles versions
- Suppression des anciennes instances
- Gestion du rollback
- Gérer les déploiements par zone avec Stacksets
Centraliser les logs
Au niveau du contrôle de l'exécution, vous pouvez utiliser CloudWatch pour accéder aux logs et au temps d'exécution de vos lambdas. Pour aller encore plus loin, le service X-Ray permet d'analyser l'intérieur même du code de votre fonction.
Elles sont cuitas les bananas ?
Mais avant de vous lancer dans le grand bain du serverless, il faut connaître toutes les contraintes.
La plus importante réside au niveau du lockin des vendors. En effet, avec les lambdas, vous travaillez en vase clos et devez utiliser les services Amazon pour votre base de données, le cache, le stockage de fichiers…
Un autre point à ne pas oublier, et qui est intrinsèque au FaaS, concerne la notion de stateless qui oblige à bien penser comment stocker et gérer sa configuration. De la même manière, vos instances sont éphémères et peuvent être détruites pour de nombreuses raisons :
- Scalabilité à la baisse (AWS coupe les instances en “trop”)
- Inactivité supérieure à 15 minutes
- Déploiement d’une nouvelle instance (qui remplace les anciennes)
- Plantage de la fonction
- Mise à jour interne AWS
À noter aussi certaines limitations techniques comme le timeout d'exécution () à ou encore la taille du payload max ().
L'affaire cold start
Enfin, évoquons le point le plus important : le cold start.
Ce sujet a fait couler beaucoup d’encre car il représente sûrement le point le plus critique d’une architecture de ce type. En effet, si AWS doit créer une nouvelle instance de votre fonction pour répondre à une nouvelle demande, il va démarrer l’instance. Ce démarrage a un coût de plusieurs centaines de millisecondes.
Si vous interrogez régulièrement vos lambdas à flux continu, vous n’aurez jamais de problématique de temps d'initialisation. À l’inverse, vous pourrez percevoir quelques ralentissements lors des appels à vos fonctions.
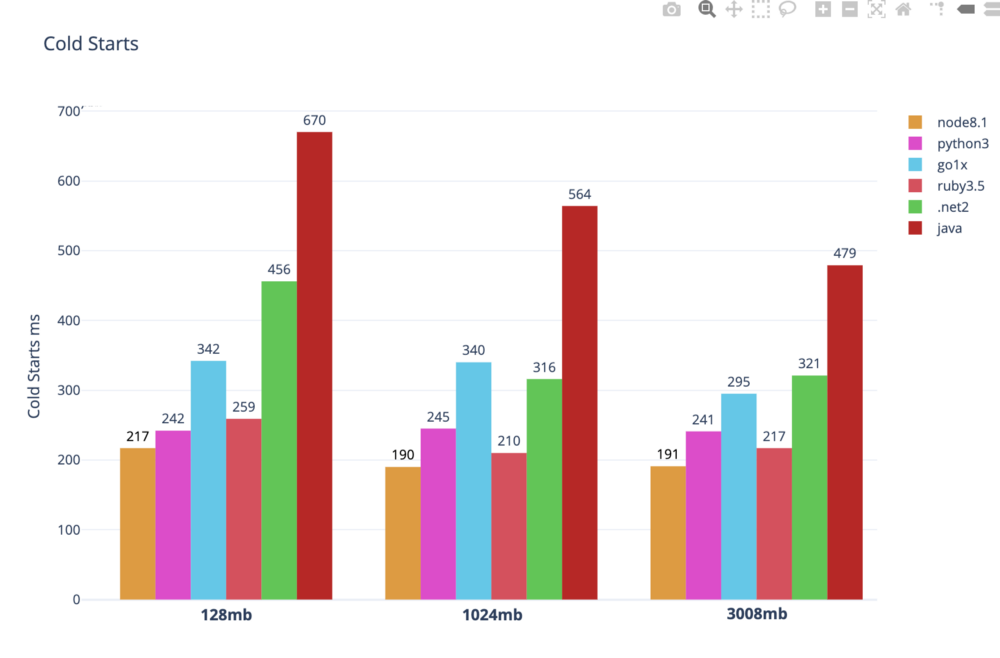 https://levelup.gitconnected.com/lambda-cold-starts-language-comparison-%EF%B8%8F-a4f4b5f16a62
https://levelup.gitconnected.com/lambda-cold-starts-language-comparison-%EF%B8%8F-a4f4b5f16a62
Ce schéma montre que chaque runtime n’a pas le même temps de démarrage. Si la performance est un sujet pour votre projet, orientez-vous directement vers des langues rapides au démarrage.
Autre levier d'optimisation, la limitation du nombre de dépendances qui va accélérer le démarrage. Vous pouvez aussi garder artificiellement en "vie" des instances en réalisant des appels avec CloudWatch Events. Plus récemment, AWS a mis en place une solution moins bricolée avec le Provisioned Concurrency. Avec cette solution, vous pouvez simplement indiquer un nombre d'instances minimum démarrées.
A quel prix ?
Le coût d’utilisation de votre Lambda est en fonction de sa consommation. Il y a deux composantes à prendre en compte :
- Le prix de l’instance créée qui va dépendre du type d’instance (en fonction de la RAM) choisie
- Le temps d'exécution
Par exemple, vous paierez 25 cts le million d’appels sur des exécutions < 100ms. Dans le cas d’une instance de 512 Mo, appelée 3 millions de fois pour un temps d'exécution de 1 seconde, vous paierez environ 18 €.
Cela reste donc très raisonnable mais n’oubliez pas que généralement, vous utilisez d’autres services avec votre Lambda qui sont aussi facturés à la consommation.
C'est bien compliqué !
Oui c'est certain qu'une architecture serverless demande quelques notions qui sont différentes en fonction du provider. Une solution existe pour abstraire et simplifier la gestion de vos fonctions au sein d'un projet : Serverless Framework.
J'aurai le plaisir de publier rapidement un article sur le sujet.
*Stateless = Ne stocke pas d'information **Serverless = N'est pas hébergé sur un seul serveur mais sur un ensemble de serveurs (cloud)
-
 Créez votre assistant personnel grâce à Gmail et ChatGPT 4
Créez votre assistant personnel grâce à Gmail et ChatGPT 4Il y a 5 mois
Les LLMs, ou Large Language Models, comme ChatGPT, Llama2, Claude ou encore Mistral nous donne un avant-goût du futur des assistants virtuels tels que nous les connaissons avec Google, Siri ou Alexa. Pourtant, il manque une sacrée touche personnelle avec ces assistants nouvelle génération. Même si OpenAI a mis en place un système permettant d’à peu près personnaliser son expérience avec ChatGPT, nous sommes loin d’avoir des IA qui nous connaissent réellement. La raison est assez simple : ceux-ci n’ont pas accès à vos données. Et si on aidait ces LLMs si puissant en leur donnant des données pour qu’ils sachent répondre à des requêtes très personnalisées ?
-
 Tests automatiques fonctionnels d’applications 2D/3D
Tests automatiques fonctionnels d’applications 2D/3DIl y a 2 ans
Comme nous le disions dans cet article, l’automatisation des tests dans le développement logiciel est indispensable : dès lors qu’une application commence à avoir un minimum d’importance, les tests automatiques permettront de gagner énormément de temps en évitant de reproduire ad vitam æternam les mêmes tests manuels, et éviteront beaucoup de régressions. Dans cet article, nous allons présenter différents types de tests automatiques dans le cadre plus spécifique d’applications 2D/3D, puisque c’est ce que nous faisons ! Cela va du test basique qui clique sur 3 boutons aux tests de plusieurs minutes reproduisant les actions comme un véritable utilisateur. Accrochez-vous, c’est parti !
-
 Collaborer en réalité virtuelle : retour d'expérience et tour d'horizon des outils disponibles
Collaborer en réalité virtuelle : retour d'expérience et tour d'horizon des outils disponiblesIl y a 4 ans
En ces temps de télétravail et de confinement, pouvoir collaborer avec ses collègues le plus naturellement possible est un enjeu majeur pour être aussi efficace que possible et pour conserver le lien social fort qui nous relie tous chez Wanadev (les copains vous me manquez déjà !).
-
 La culture de l'open source chez WanadevRecherche et développement
La culture de l'open source chez WanadevRecherche et développementIl y a 4 ans
Chez Wanadev, l'utilisation et la contribution à l'écosystème open source est aujourd'hui une évidence, et ce n'est pas prêt de changer : c'est inscrit dans notre ADN. Dans cet article, et dans quelques autres qui vont suivre, je vais vous expliquer pourquoi et comment l'équipe contribue à l'open source, et quelle est notre culture d'entreprise à ce sujet.
-
 Le meilleur cloud est celui qui n'existe pas encore !Recherche et développement
Le meilleur cloud est celui qui n'existe pas encore !Recherche et développementIl y a 4 ans
Ce n'est plus à démontrer, le monde actuel fonctionne en grande partie grâce à internet. En coulisses, de nombreux acteurs techniques fourmillent pour proposer des solutions adaptées à la forte croissance du marché et aux nouveaux usages. Entre eux, la concurrence fait rage et le cloud est le nouvel eldorado. Côté consommateur, l'offre paraît complexe et suscite souvent plus de questions que de réponses.
-
Blend Web Mix 2019 : quelques retours sur ces deux jours !Recherche et développement
Il y a 4 ans
La Blend Web Mix, qui s'est déroulée les 13 et 14 novembre cette année, est une occasion de rencontrer d'autres professionnels du Web, d'échanger et bien sûr de s'informer sur des sujets variés grâces aux conférences. Il y en a pour tous les goûts : technique, design, business, il y a forcément une conférence pour vous !




Commentaires
Il n'y a actuellement aucun commentaire. Soyez le premier !